“Everything on Paper Will Be Used Against Me:” Quantifying Kissinger is a textual analysis project by Micki Kaufman, a digital historian that focuses on large-scale projects involving data analysis and visualization. The project tackles a new problem modern historians face: the overwhelming quantity of data that complicates forming historical interpretations. Kaufman’s project handles this problem by using computational textual analysis to form visualizations of approximately 17500 meeting memoranda and teleconference transcripts that have been released by the Digital National Security Achieve.
The documents belong to Henry Kissinger, a man who served as the United States Secretary of State and as the National Security Advisor, where he influenced American foreign policy regarding China, the Soviet Union, Vietnam, and the Middle East under Nixon and Ford.
Text Analysis Methods
All the document’s metadata were converted into a table that was organized and analyzed by OCR. The OCR resulted in approximately a 6% margin of error. The website notes that if the OCR process incorrectly recognizes a word as another correctly spelled word (e.g. sea/see) it would be not counted as an error. This means that the possible number of errors could be higher than the initial 6% figure. I am concerned about the accuracy and the viability of the data when the error rate is likely higher than 6%; even Kaufman is unsure of how much greater the error rate could potentially be.

The data organized was used to form a visual network of words that were closely related to each other. For instance, the word “bombing” was a frequent word in the teleconference transcripts, and it also happened to be well connected with words relating to “Vietnam”. While the connection between “bombing” and “Vietnam” is quite obvious to any person with even a cursory interest in Cold War history, I can see how the networks between frequent words could be useful to find potential connections in history that historians have never considered before—especially when historians are met with a deluge of information.
The visual network of words is interactive, and while it is something that sounds neat, due to the cluttered layout of the visualization it is difficult to clearly see the connections between the desired words. The problem is that while the viewer can highlight a network, the viewer is still able to see all the other networks, leading to a visual mess that can be headache inducing when trying to look at a specific network.

The Value of the Project
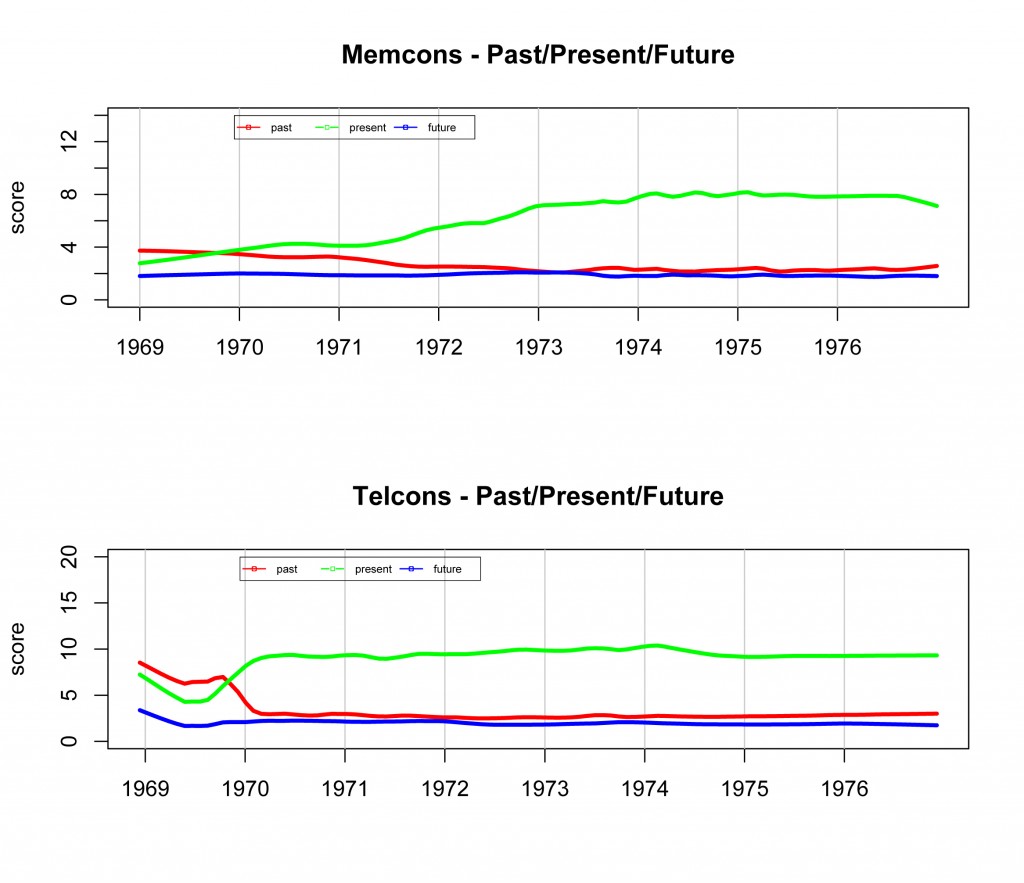
The project offers new insight into tackling historical big data in innovative ways. By analyzing the language of Kissenger, Kaufman engages in “sentiment analysis” that displays Kissenger engaging in more past tense language rather than future tense language despite his reputations as a “forward-thinking master”. While I still have concerns about the error rate regarding OCR, new analysis like this would have been unthinkable if humans had to manually peruse through 17500 documents. Even if the new analysis may not be perfect, it sparkes new questions and possible connections that would have been missed before, therefore I think this project is valuable.
Representation
The Quantifying Kissinger Project was created by Micki Kaufman, a woman in digital history. This project does not make much mention of representation because the salient purpose of the project is to focus on a single historical figure: Henry Kissenger.
Final Thoughts
The ability for a project to draw connections from 17500 documents is something that is impressive. While this project brings new questions and angles of analysis to a large number of documents, it does not explain the significance of the connections: it merely points them out. It is up to the historian to draw the significance between connections. This project demonstrates the benefit of computer analysis: expediting the more tedious work to leave historians with more time to think about the significance of the connections. While Kaufman could have done a better job of accounting for the errors in the analysis, the sheer magnitude and ambition of this project merit an examination of this project to anyone that is interested in Kissenger or the Cold War.
Good overview Daniel. A single-digit error rate in OCR is very good. For a lot of historical sources is it closer to 20 percent. Hopefully, this will improve with more AI solutions in the coming years. But, this still means you have a sample size in the 90s for this source or 80s for other sources, so you can start to find statistically relevant connections, particularly when you’re using a lot of data. But the errors remain a problem, particularly with false positives where a common error creates a word that is relevant and messes up the analysis.